通用爬虫介绍和实现思路
通用爬虫四个字很简单,通用的爬虫,一份爬虫,可以爬多个网站,对于小白就可能有点难以想象。
像我最开始学习的,那些全站爬虫,增量爬虫,通用爬虫,爬虫管理系统,爬虫框架,分布式这些高大上的词对于当时还是个小白的我来说也是大脑一片空白,完全想象不到。
那么这一集我们来看看这个通用爬虫到底是个什么东西,如果实现一个的话大致可以怎么实现一下。
资源数据网站:新闻,博客【搬运】,音乐,视频【备份】,图片【表情包,壁纸】
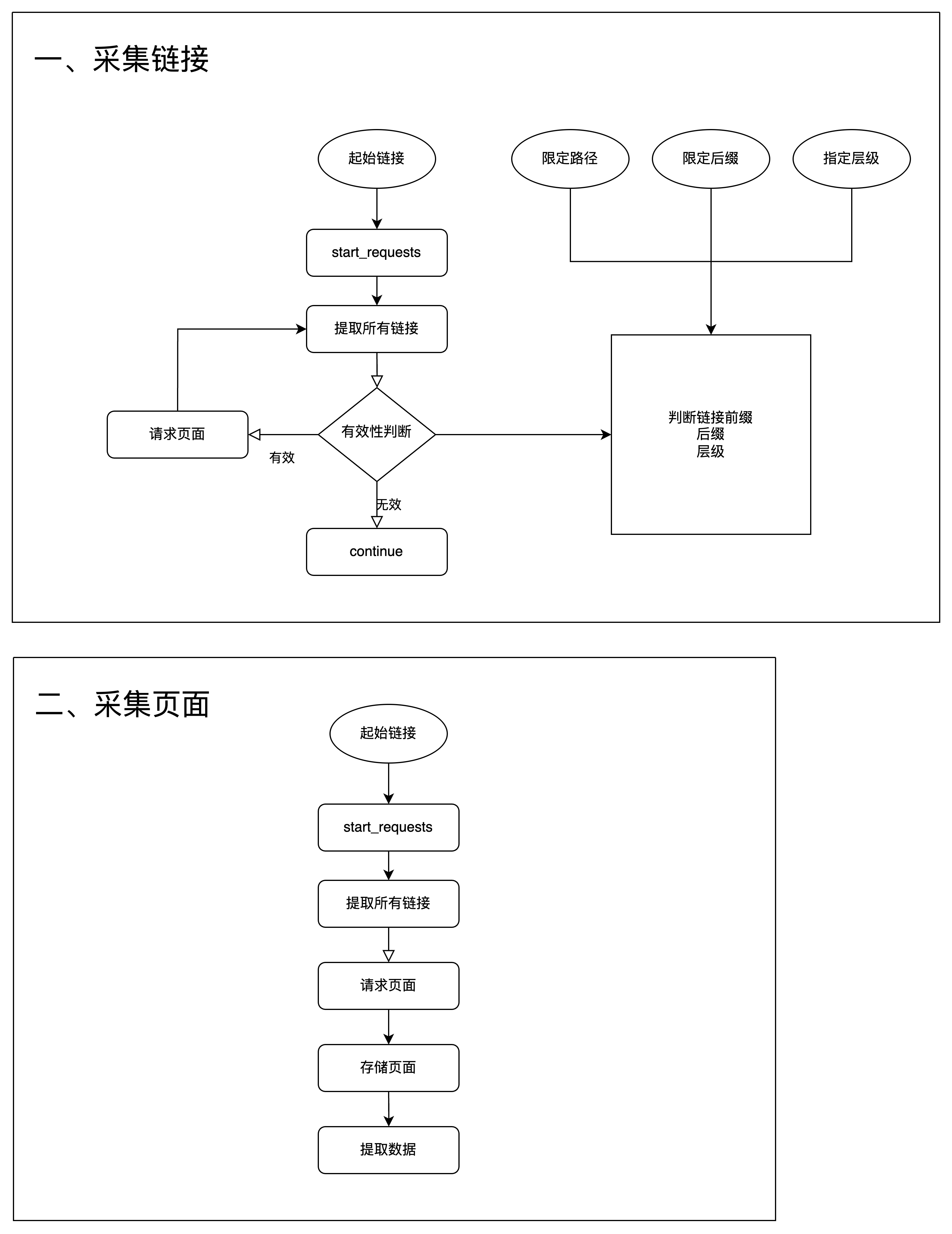
一般流程如下:
- 采集合集列表页【等价个人主页,类别合集页面】【财经,科技,全球】【/categories】
- 采集每个列表页【列表页的新闻】【/category/web3,/category/global】
- 采集详情页【新闻详情】【/article/1,/article/2】
- 解析详情数据【时间,标题,内容】
- 数据分析->可视化->聚合...
实现